今天 n8n 群里有群友遇到了这样一个问题,他使用 HTTP Request 节点访问一个网页。但因为该网页的编码为 GBK,不是 UTF-8,导致 n8n 后续节点无法正常读取处理这个数据(比如提取正文)。这要怎么办呢?
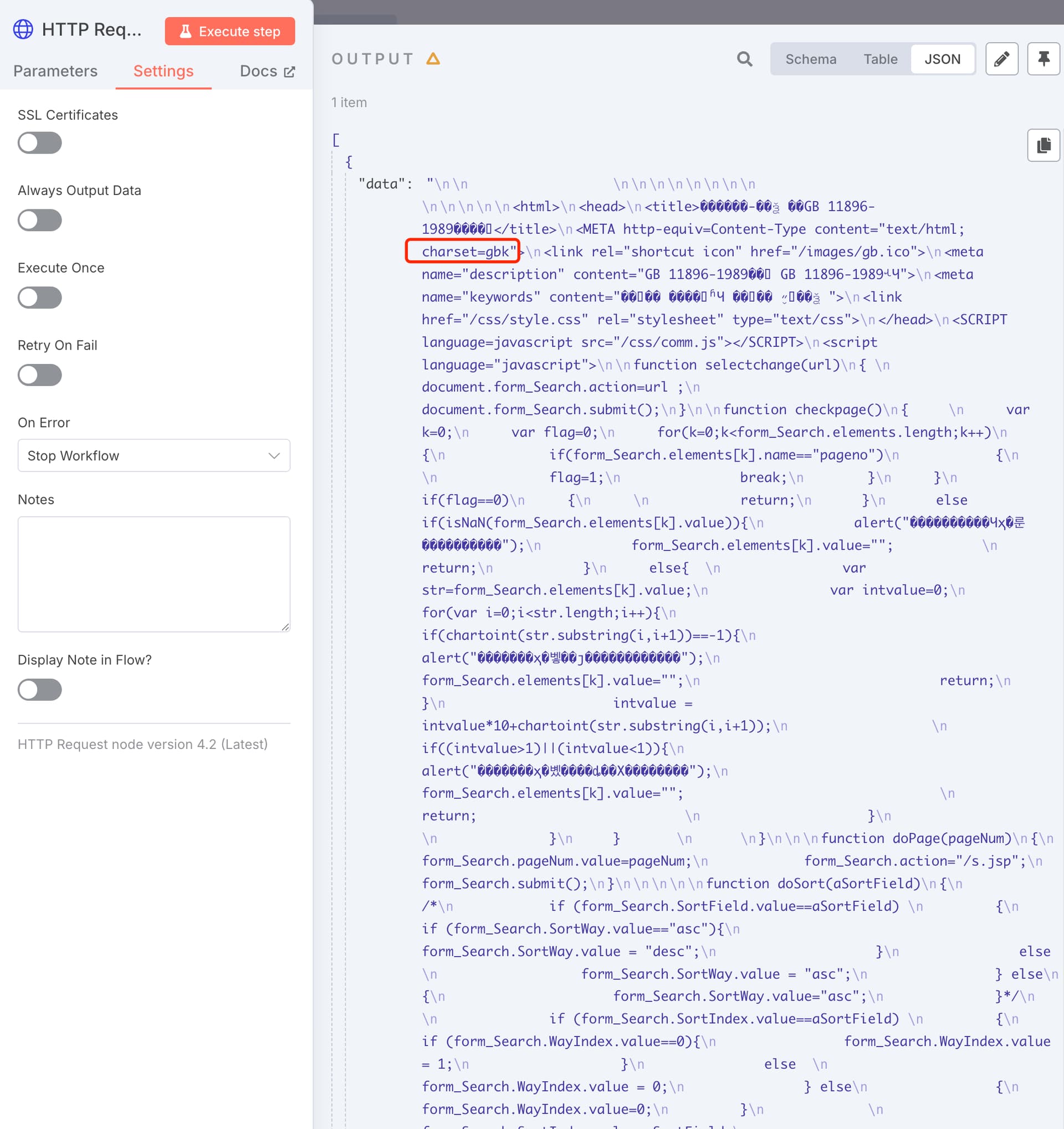
n8n 的 HTTP Request 节点默认只能处理 UTF-8 编码的网页,如果要处理非 UTF-8 的网页,需要将网页作为一个二进制文件来重新载入。
具体来说是这样:

增加一个 Extract From File 节点,加载 HTTP Request Get 到的网页。
然后,在 Extract from File 节点的可选项中,打开 File Encoding 这个选项,切换为 Expression 模式,手工输入你的编码格式:
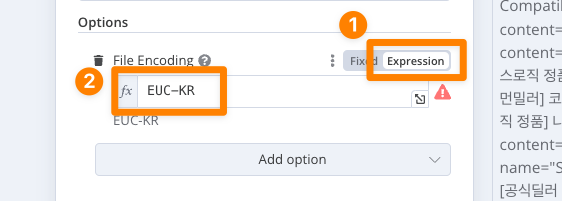
这里的截图是从官方论坛的帖子里面截图的,是个韩文编码。对于群友的情况来说,只要把这里的 EUC-KR 改为 GBK 就行了。
之后,从 Extract from File 节点输出的数据就是正常可以被 n8n 处理的数据了。