在使用 API 调用 AI 的过程中,我们有的时候会处理或输出一个超长列表。比如一次性输出 20 个或 30 个什么样的项目。
但除非在最强模型下(如 Gemini 2.5 Pro 或 GPT-o3),AI 有时不会遵从 prompt 中的输出条目限制。
比如在基于海量新闻生成要闻日报的场景,你希望它输出不少于 10 条,且不超过 20 条的摘要。如果你将数量限制写在 System Instruction 里,会发现 AI 经常自顾自的生成二十多条。
又或者是,你给了 AI 一个 200 行的数据,希望它生成精准对位的 200 行对应 tag 出来。而 AI 可能生成到 100 个就罢工了,或者到了 200 还在生成。
这时候有两个技巧,可以改进模型对这种 prompt 限制的遵从性。
- 将硬性输出要求,放置在待处理素材之后,也就是以这种结构调教 prompt:
System Instruction:你正在制作一份周报 巴拉巴拉巴拉巴拉,以下是待处理的素材:
User:【待处理素材块】
System Instruction:在你生成周报时,将按照重要性选取最重要的 10~20 条保留,永远不要低于 10 条,不要超过 20 条。
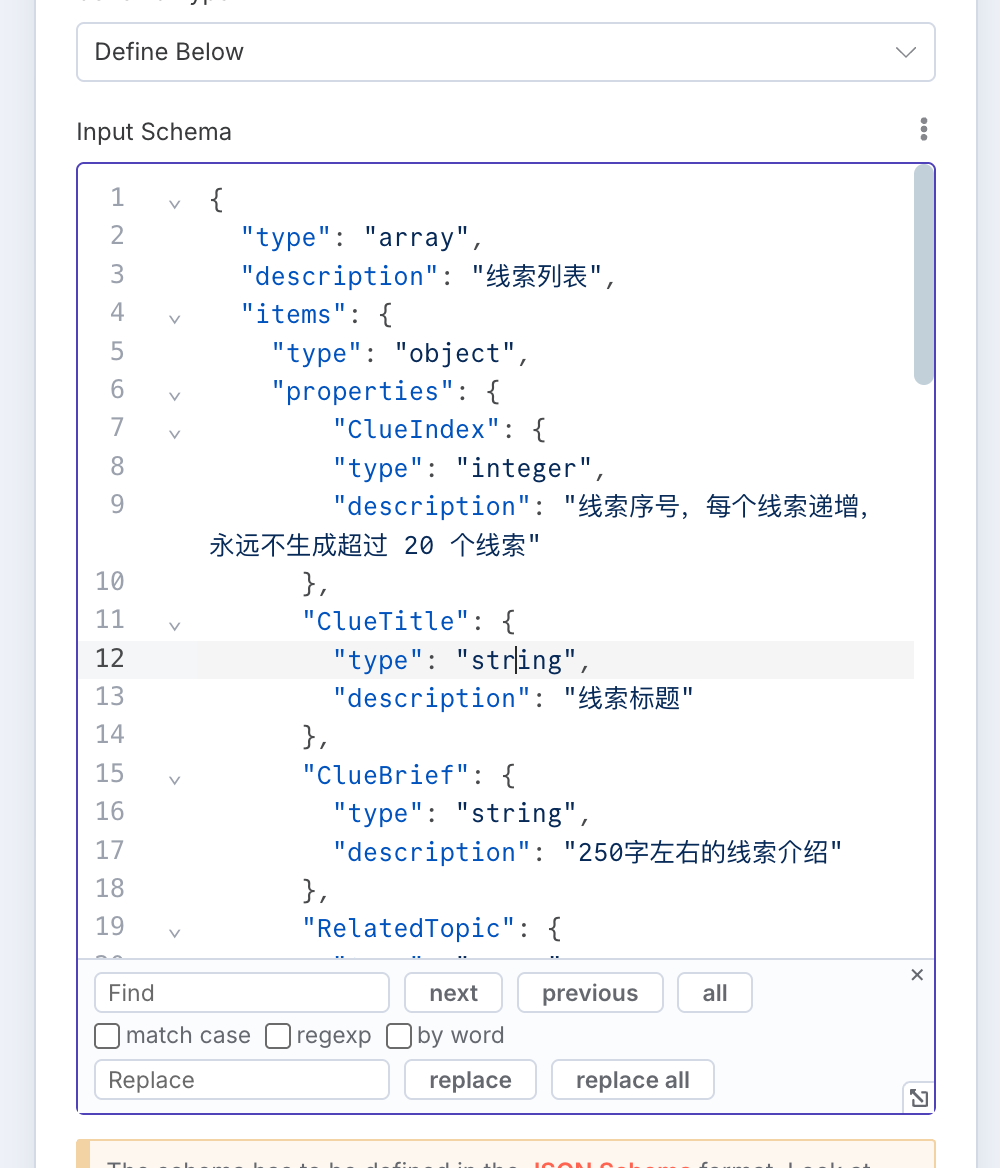
- 将硬性输出要求,写进 json Schema,具体方法如下:
在约束输出的 json Schema 中,除了你必要的那些 properties 之外,增加一个名为 index 的整数 property,并将其描述为“项目序号,从 1 开始,每个项目递增,永远不生成超过 20 个项目”,这可以在模型生成的过程中,不断反复提醒数量约束,几乎可在 Gemini 2.0 Flash 同级及以上级别的模型中 100% 实现数量约束
示例如下:
"properties": {
"ClueIndex": {
"type": "integer",
"description": "线索序号,每个线索递增,永远不生成超过 20 个线索"
},