Deep Research 类 AI 产品虽好,但价格昂贵,尤其是在自己复刻的时候,往往比直接买 ChatGPT 和 Gemini 的会员还贵。
因为它的原理并不复杂,但你真正开始复刻的时候会发现,比起大模型的 Token 成本,搜索 API 的成本更高。
以 SerpAPI 为例,它按搜索次数收费,每 5,000 次搜索高达 75 美元一个月。Google 官方的搜索 API 则按返回的结果数收费,每 1000 次高达 35 美元。
那,我们能不能找个免费的搜索方案来实现 Deep Research 的搭建呢?其实是有的,不仅如此,我们甚至可以不局限在一个搜索引擎里。那就是使用开源的 SearXNG 作为搜索 API。
你可以先下载这个 Workflow,导入你的 n8n 后照着教程理解:
DeepResearch_With_SearXNG.zip (7.5 KB)
在这篇教程中,你将学会如何将 Workflow 作为 AI Agent 的工具使用。这意味着,你可以在 n8n 中让 AI 调用那些既没有标准节点、也没有 MCP 的服务。
什么 SearXNG?
SearXNG 是一个免费、开源的元搜索引擎——用人话解释,就是搜索引擎代理。它会在真正的搜索引擎和用户之间做一个中间层,代理用户进行搜索。
简单来说,它的主要功能是:
- 整合搜索结果: 它不像 Google 或 Bing 那样自己建立索引,而是将用户的搜索请求发送给多个不同的搜索引擎(如 Google, Bing, DuckDuckGo, Qwant 等)和其他信息源(如维基百科、Reddit 等)。
- 保护隐私: 这是 SearXNG 的核心目标。它不会跟踪用户、不记录搜索历史、不收集个人信息。它通过作为用户和各个搜索引擎之间的代理来隐藏用户的 IP 地址,从而实现更匿名的搜索。
- 避免个性化和过滤气泡: 由于不跟踪用户,它提供的搜索结果通常不会受到用户历史行为的影响,有助于用户获得更广泛和多样化的信息。
在 n8n 的 1.89 版本中,加入了 SearXNG 作为一个标准节点,这意味着我们可以使用 SearXNG 作为一个搜索 API,在 n8n 中构建带有搜索功能的 AI Agent。
如何部署一个 SearXNG?
SearXNG 的部署比 n8n 还简单,它几乎是一个可以拉取镜像后直接运行的项目。
尤其是在作为 n8n 节点使用时,我们甚至不需要使用它的 Web UI。
你如果会用 Docker,只需要直接拉取镜像,然后运行就行。只有两个地方需要设置:
其一:
端口映射 9147:8080
将宿主机端口 9147 映射到容器端口 8080
其二:
永久化存储
将宿主机目录 /volume1/docker/searxng 映射到容器目录 /etc/searxng。
如果你还是不会,可以参考这个只有 1:40 秒的 B 站教程。
你需要将 SearXNG 部署在和 n8n 同样的机器上,否则需要额外的配置公网的 API 访问,这不安全。
如何配置 SearXNG?
SearXNG 部署完成之后,我们要进行一些配置才能让它在 n8n 里被使用。
在 SearXNG 的 WebUI 中修改配置,不会覆盖全局配置,意味着只对你浏览器的进程生效。所以,这部分的配置我们必须在 SearXNG 的配置文件中修改。
SearXNG 的配置文件有空敏感性,如果你在里面使用了 tab 而不是空格进行缩进,配置将不会生效。具体表现为,修改配置文件后保存,重启 SearXNG 配置文件被恢复为默认配置。在修改配置时,需特别注意与原始配置保持格式一致。
进入到宿主机的是 /volume1/docker/searxng 这个目录,打开 settings.yml 文件。
里面有几个点需要我们修改:
打开作为 API 的 json 模式
搜索 formats:,在默认的 html 下面加入 json,如下图:

打开/关闭指定搜索引擎
默认情况下 SearXNG 打开了对 Google、Wikipedia 和 Gogoduck 等国外搜索引擎的支持。如果你想打开百度搜索,你需要在配置文件里搜索 baidu。然后将 disabled: true 修改为 disabled: false。如下图:

同理,你可以查阅配置文件里其他的搜索引擎的这个设置,关掉那些你不想要的以提升检索速度。
设置代理
如果你的 SearXNG 处在一个不能访问 Google 的网络环境,你可能需要设置一下。SearXNG 不读取 Docker 的代理环境变量,需要在配置文件里修改。搜索 proxies: ,按照如下图配置即可:
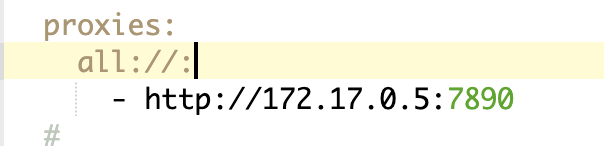
至此,你的 SearXNG 就可以作为一个好用的搜索 API 来用了。
值得注意的是,SearXNG 的 WebUI 是默认打开的,并且允许外网访问。如果你不希望别人使用你的 SearXNG,我建议你在 Docker 将端口映射改为 127.0.0.1:9147:8080。这样确保只有本机的 n8n 可以调用 SearXNG,代价是你自己也访问不到 SearXNG 的 WebUI 了。
构建 n8n Workflow
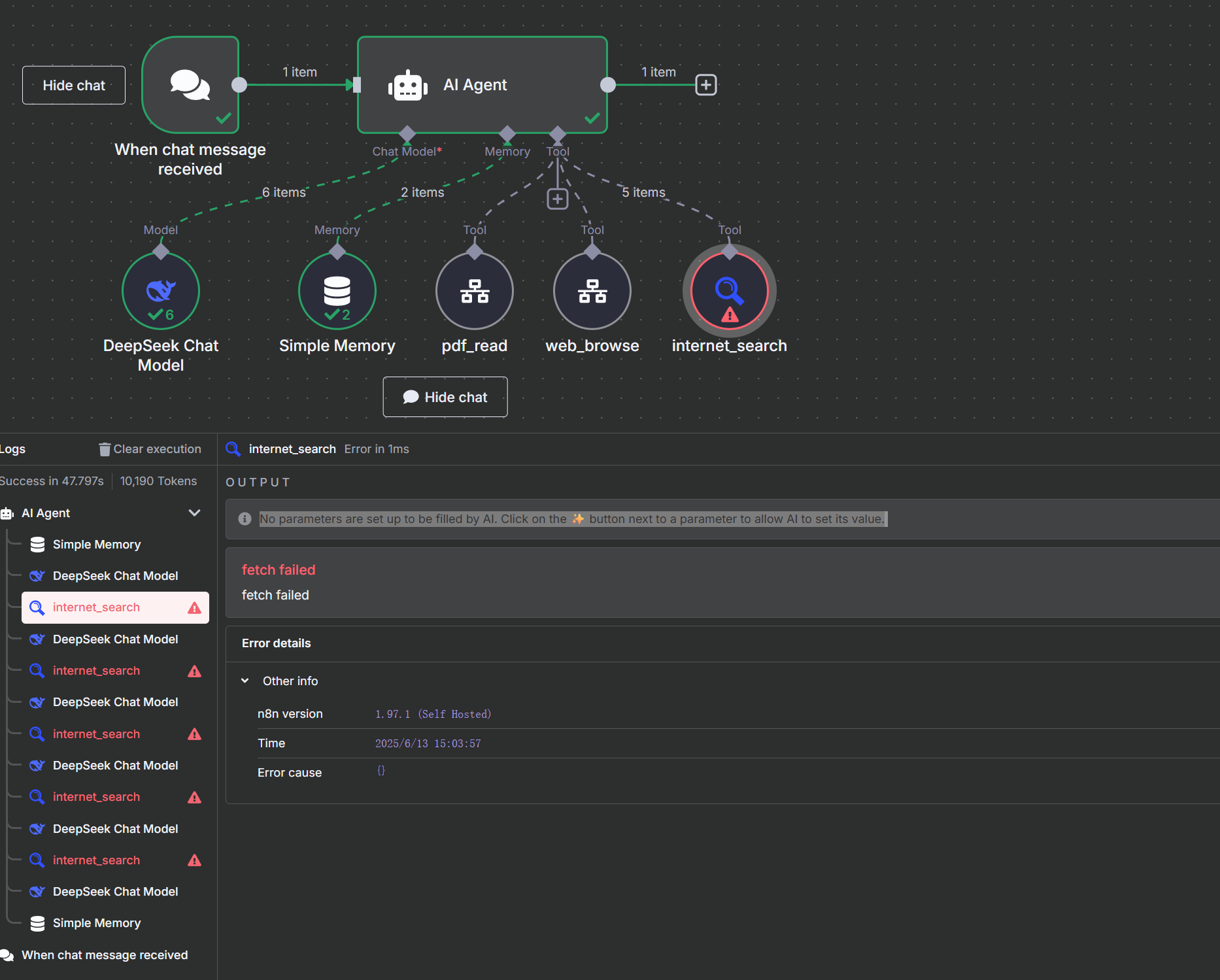
DeepResarch 想要做好有非常多的工程化细节,但我们只做原理复刻的话,就会变得非常简单。整体而言,它的 Workflow 长这样:
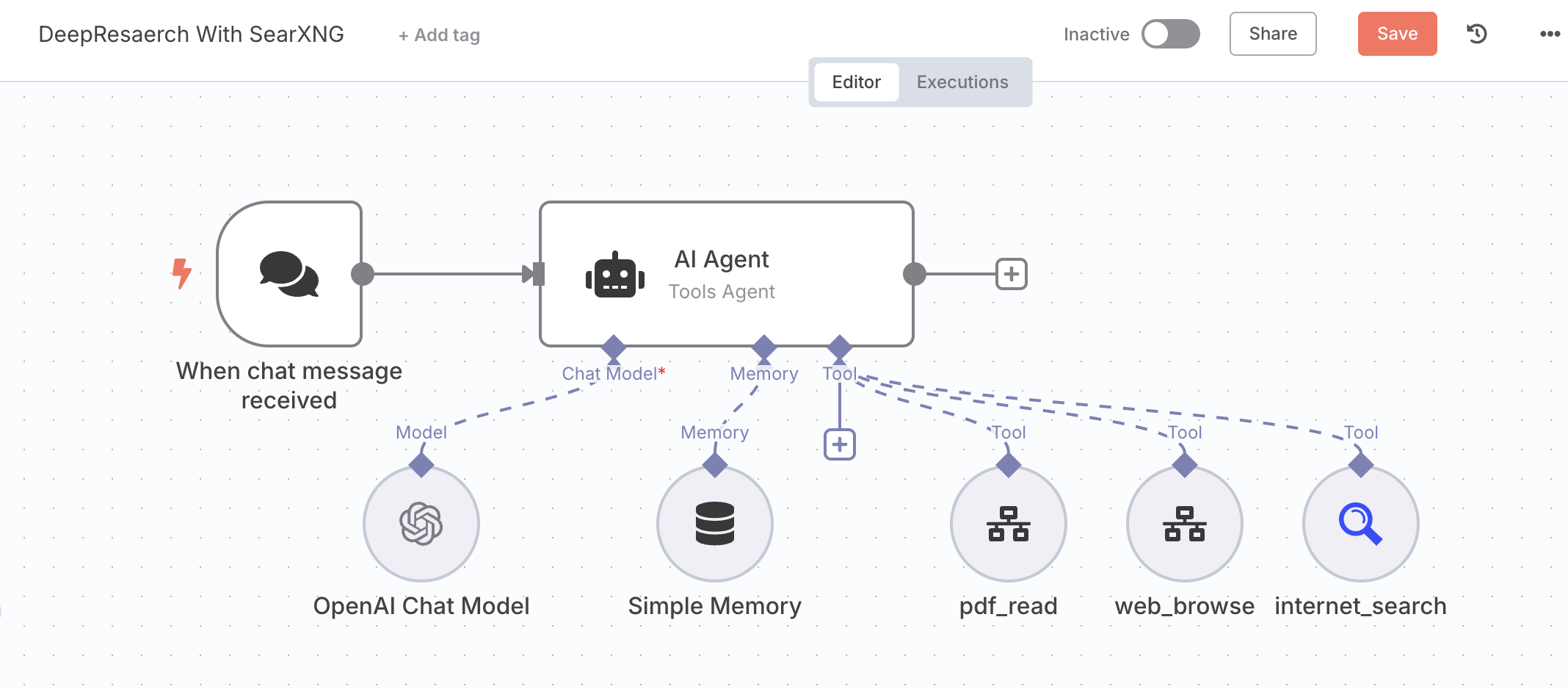
可以看到,我们实际上只是在标准的 AI Agent 工作流(一个聊天触发器、一个记忆节点、一个 AI Agent 节点和一个 AI 模型)上连接了三个工具,分别是 internet_search、pdf_read 和 web_browser。
我们一步一步来解释这三个工具如何配置。
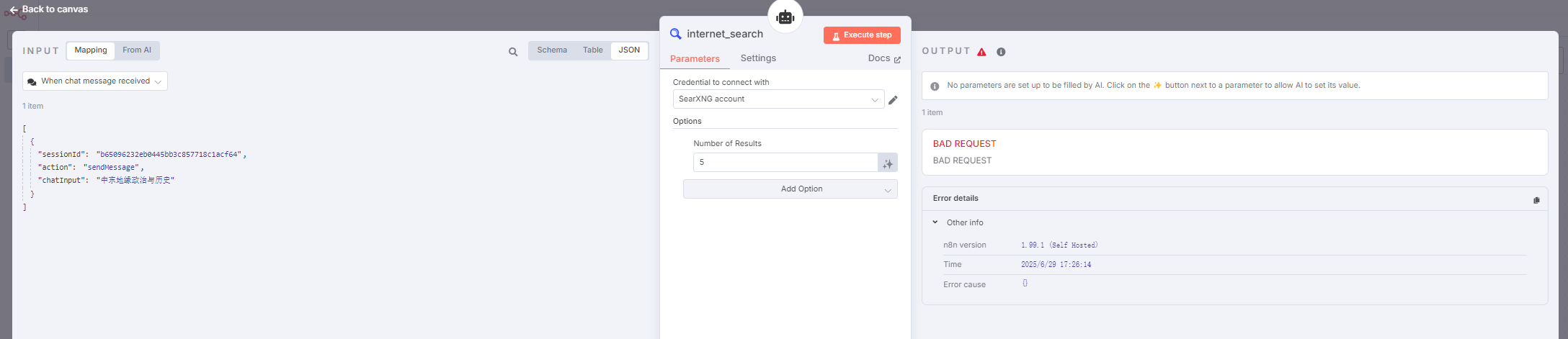
配置 internet_search
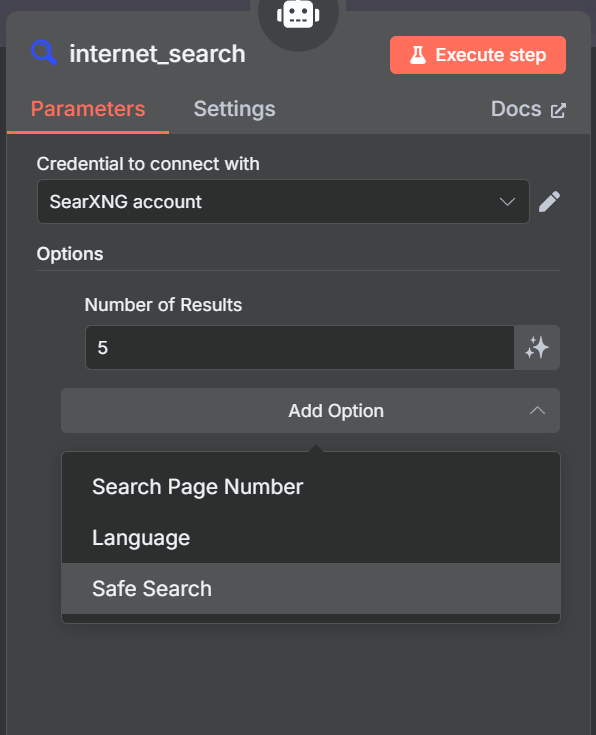
直接在 AI Agent 的 Tool 槽位上点击加号,选择 SearXNG 节点。
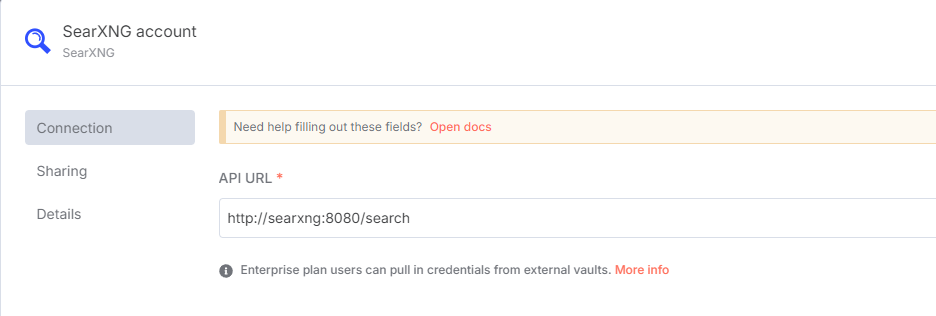
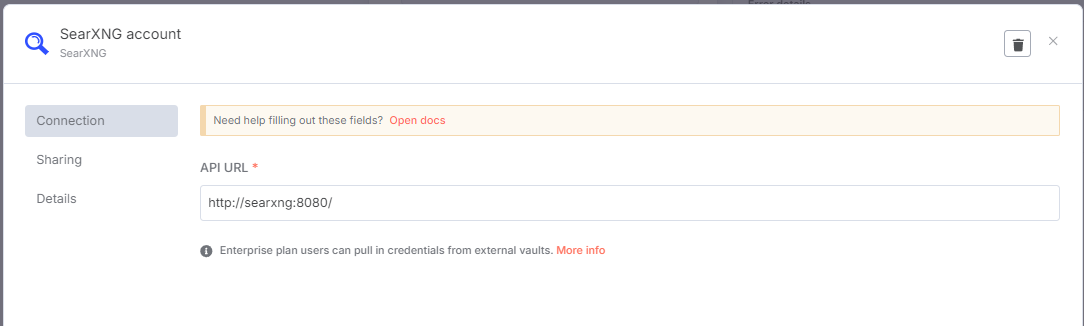
在弹出的节点配置中,我们选择新建一个 SearXNG 凭据(Credential)。然后,将我们刚才配置的 SearXNG 的地址填写进去:
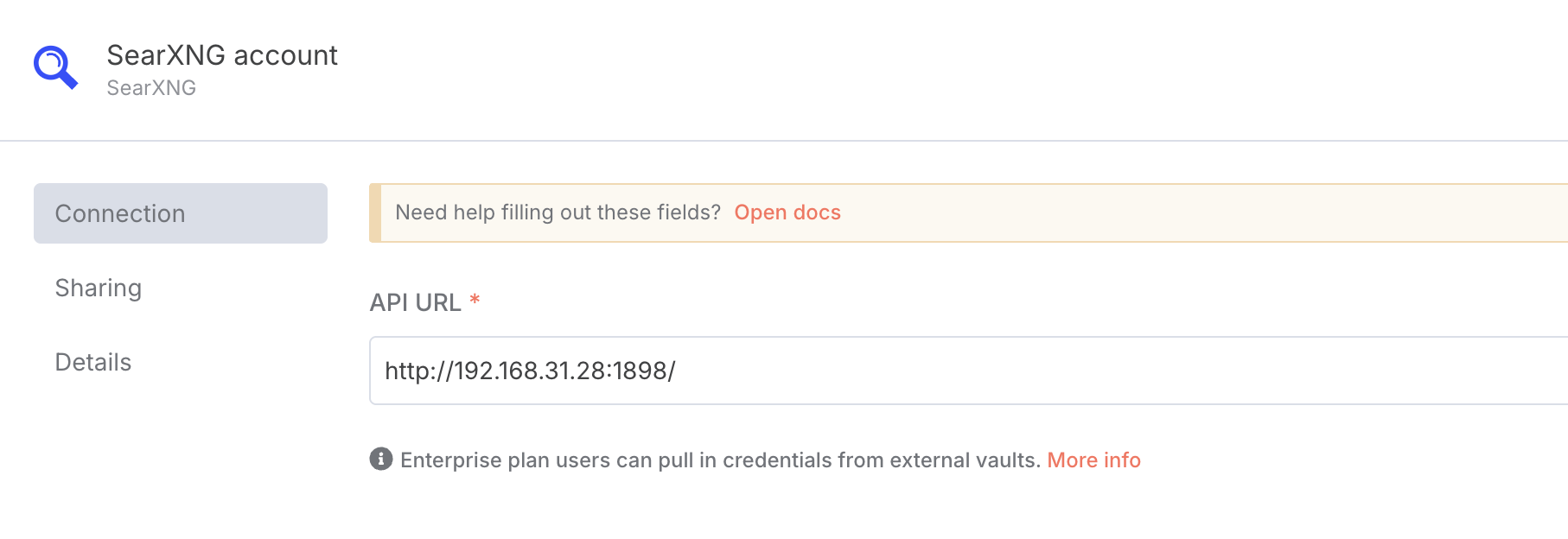
这里要填写的地址,是你的 SearXNG 的本地地址。至于什么是本地地址,你需要参阅这个说明:
至此,我们的搜索工具配置完毕。
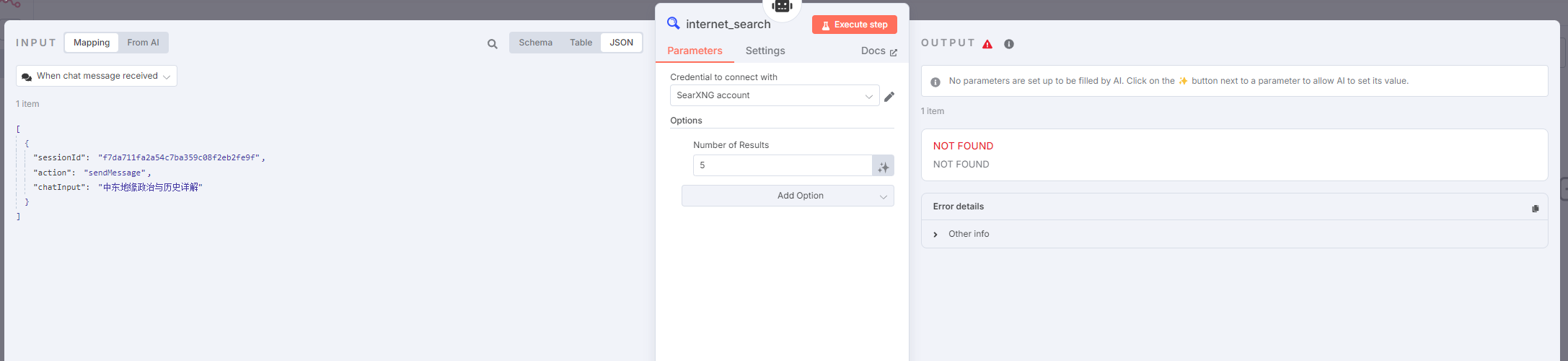
但是,我们会发现 SearXNG API 返回的搜索结果,而非结果页内容。也就是它给的其实是某个关键词搜索后 Google 列表的那个页面——标题、网页地址、一小段摘要。
我们为了让 AI 能真正从搜索结果中提取有用信息,必须让 AI 实际读取搜索结果页面才行。这就导致了我们需要配置另外两个工具,一个用来读网页,一个用来读 PDF。
配置 web_browser
我们当然可以直接把 HTTP Request 节点作为一个工具接到 AI Agent 上,但那样就意味着 AI 在研读网页的时候,会把整个网页的完整 HTML 都放进上下文里。一方面影响 AI 的阅读能力,另一方面会大幅的增加 Tokens 消耗。
为了减少 AI 的阅读负担,我们希望能够将一个网页先转换成 Markdown 再喂给 AI。
然而,在 AI Agent 节点上,我们只能单独使用一个节点作为工具,怎么办呢?
我们可以单独建一个用于读取并转换网页的 Workflow,再把这个 Workflow 作为工具连接在 AI Agent 上。
首先,我们创建一个新的 Workflow,随便取个名字,然后配置上如下节点:
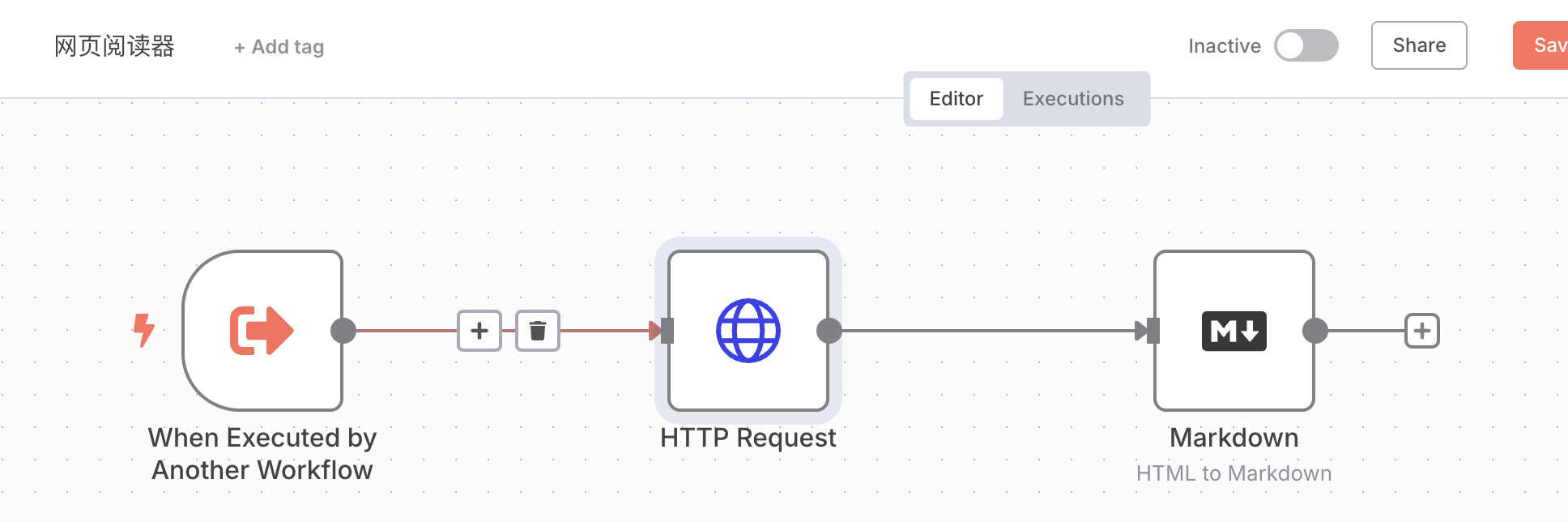
它的触发器是“When Executed by Another Workflow”,这个触发器专门用于编排子 Workflow。它允许你设置这个 Workflow 需要从父 Workflow 索要哪些参数。比如在这里,我们实际上只需要一个参数,那就是 URL,也就是想要阅读哪个网页。我们就这样设置:
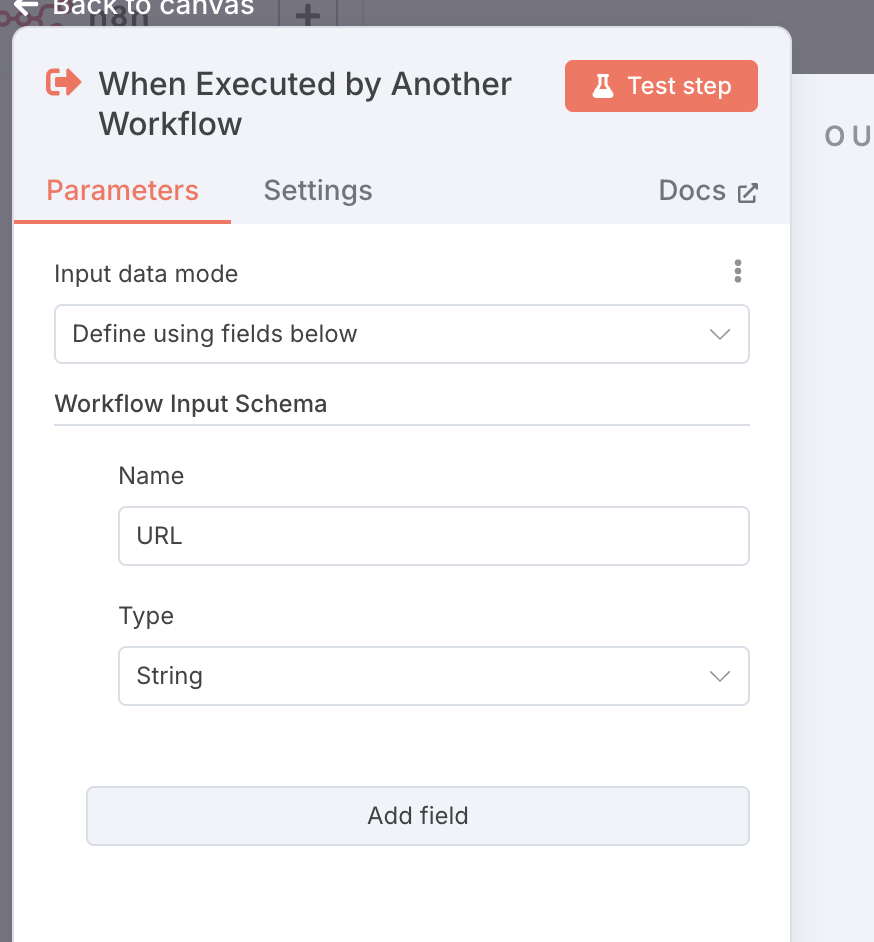
接下来,我们添加一个 HTTP Request 用于获取网页,设置如下:
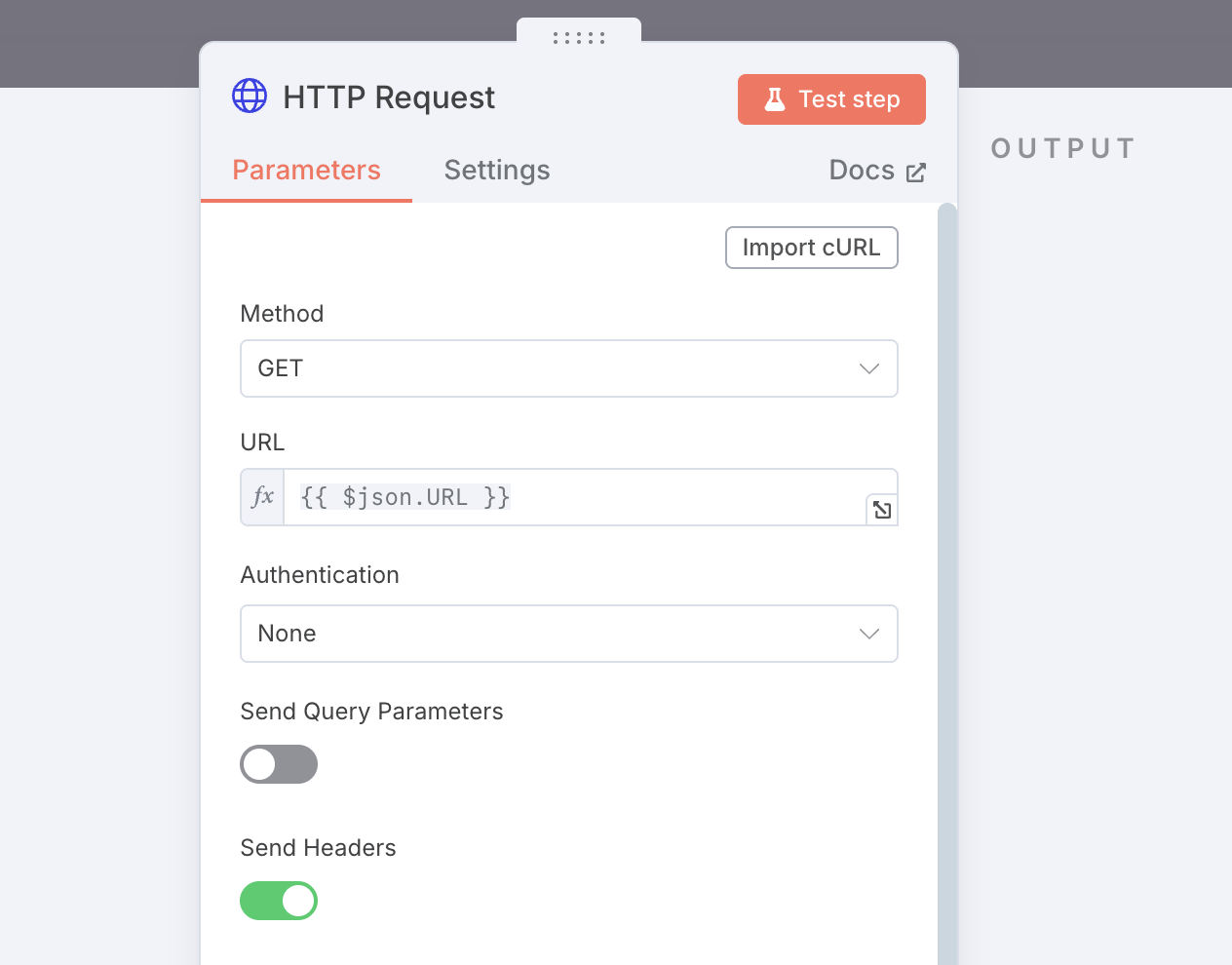
获取完的网页,我们需要用一个 Markdown 节点去剥离它的所有 HTML 代码只保留大部分能直接看的肉眼内容,配置如下:
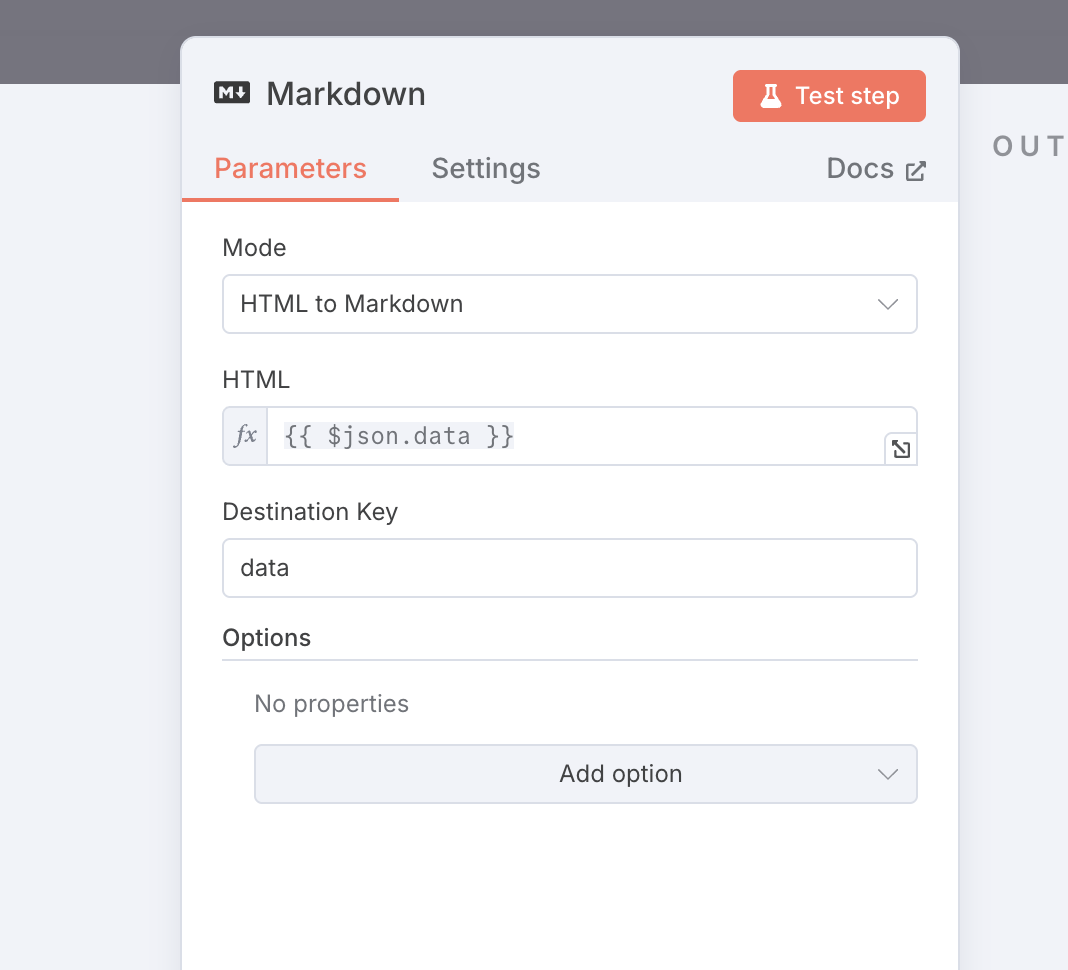
这样,我们一个用于将指定 URL 转换为 Markdown 的子 Workflow 就做好了。
此时,我们回到我们的父 Workflow,在 AI Agent 的 Tools 槽位上增加一个 Call n8n Workflow Tool:
Source 选择 Database,Workflow 选择我们刚才做的子 Workflow(网页阅读器):
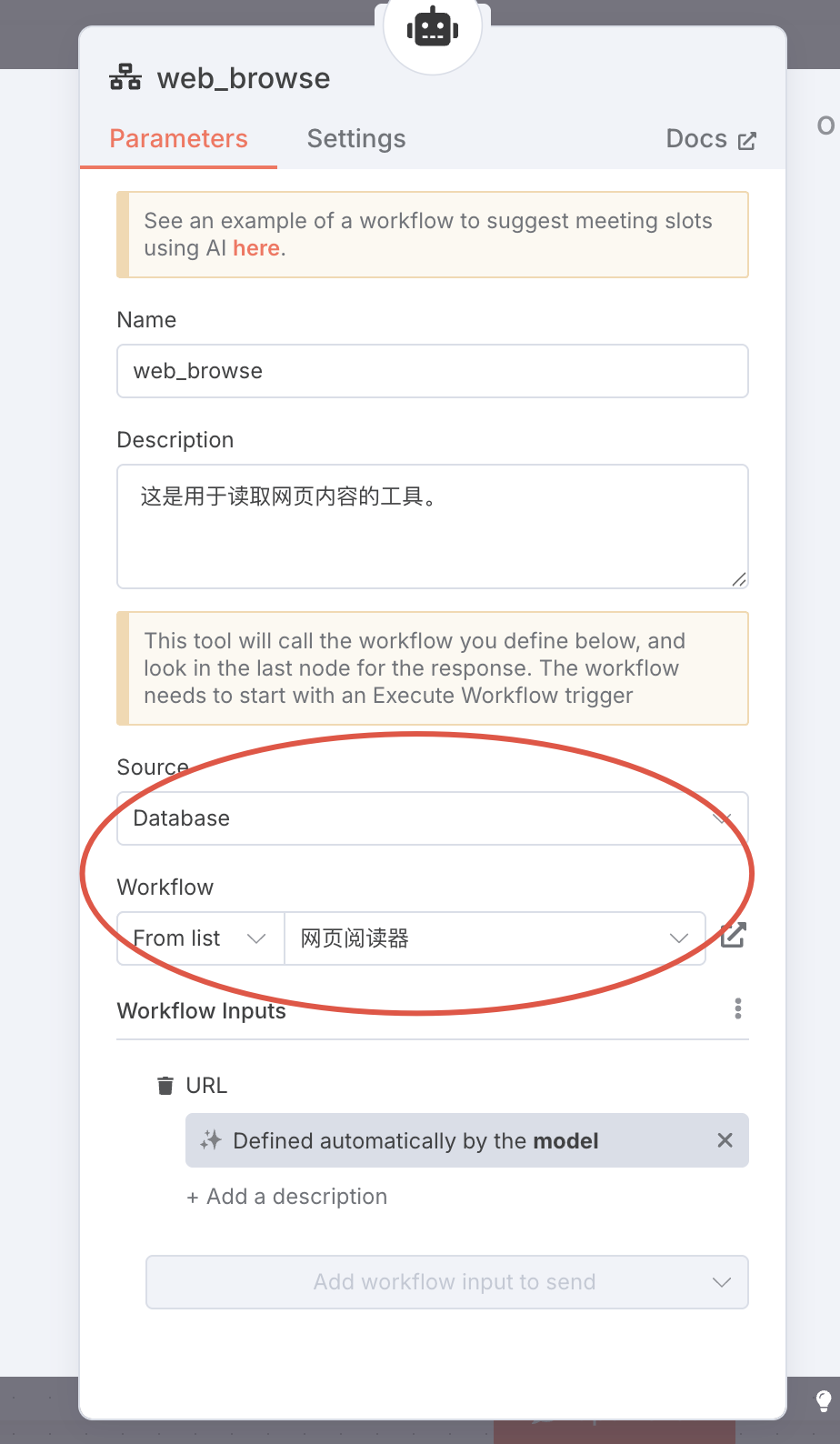
这个时候,我们会发现刚刚被我们定义的参数已经显示在了下面(URL),然后我们勾选 AI 自动填写。
再为这个工具写一个 Description,告诉 AI 这是个什么工具,怎么用。
配置就大功告成了。
配置 pdf_reader
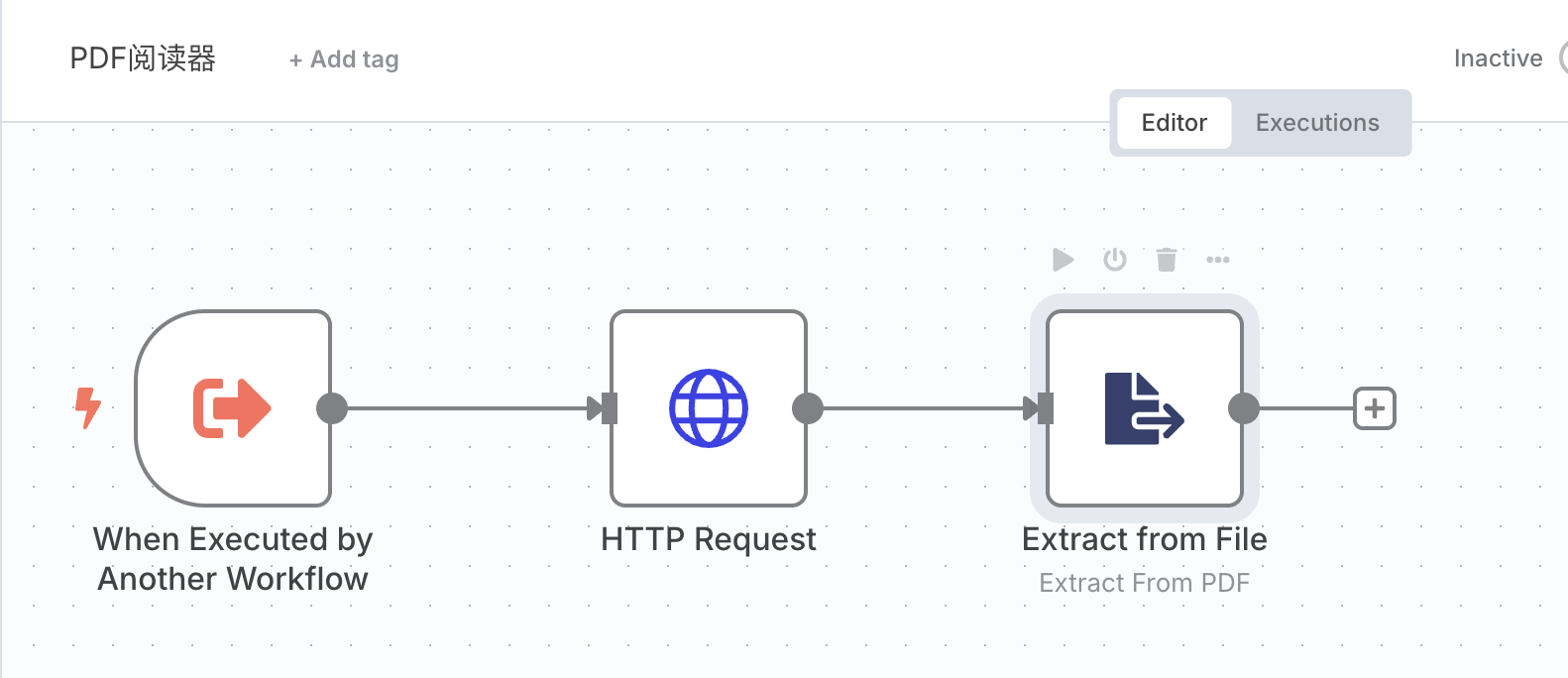
如法炮制,我们建立一个子 Workflow,设置三个节点。主要功能是将指定 URL 的 PDF 下载下来,解析成平文本。
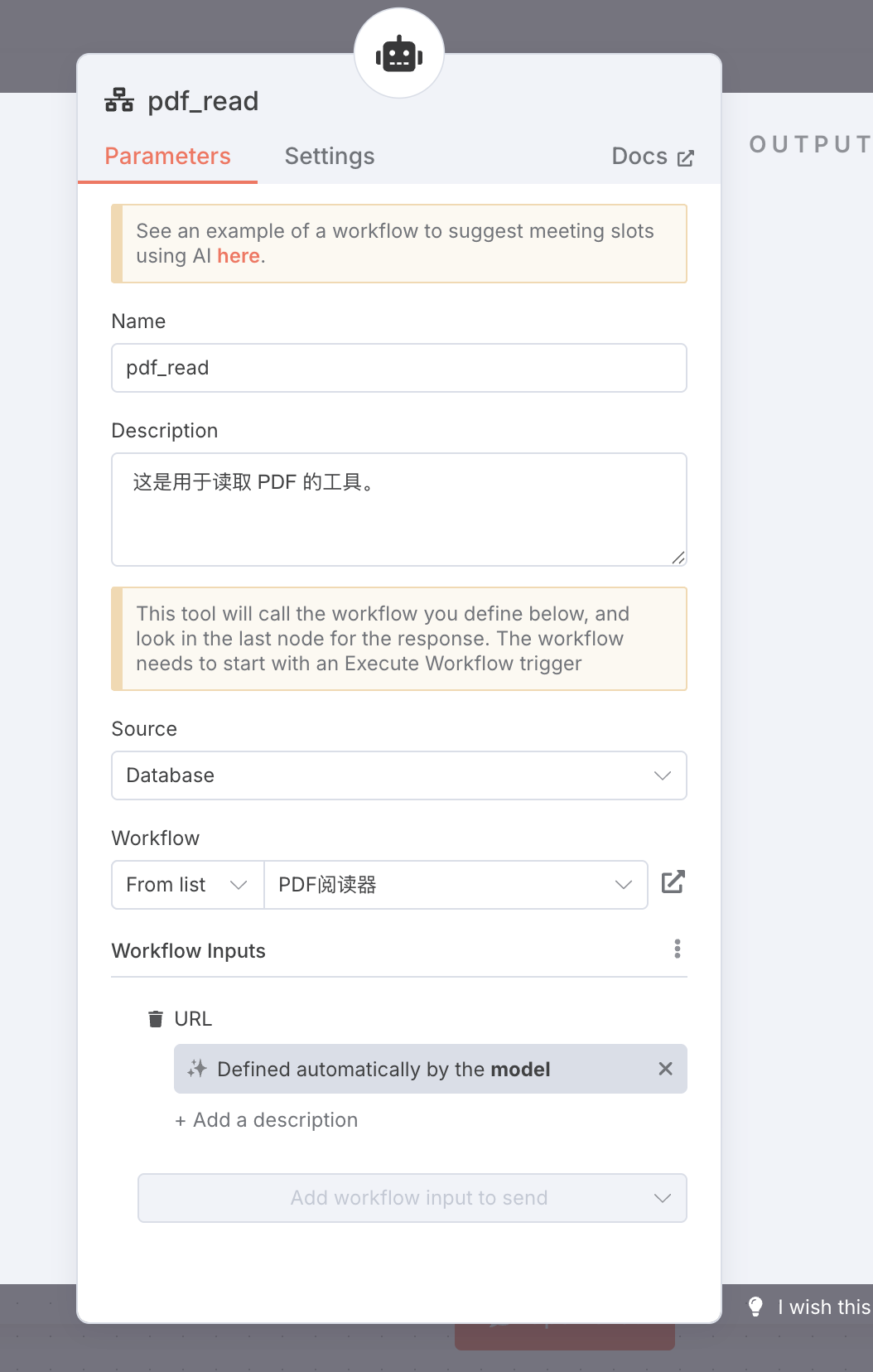
回到主 Workflow,添加子 Workflow 作为工具,配置好说明。
这样,AI 对于搜索结果中的 PDF 也就可以自动处理了。
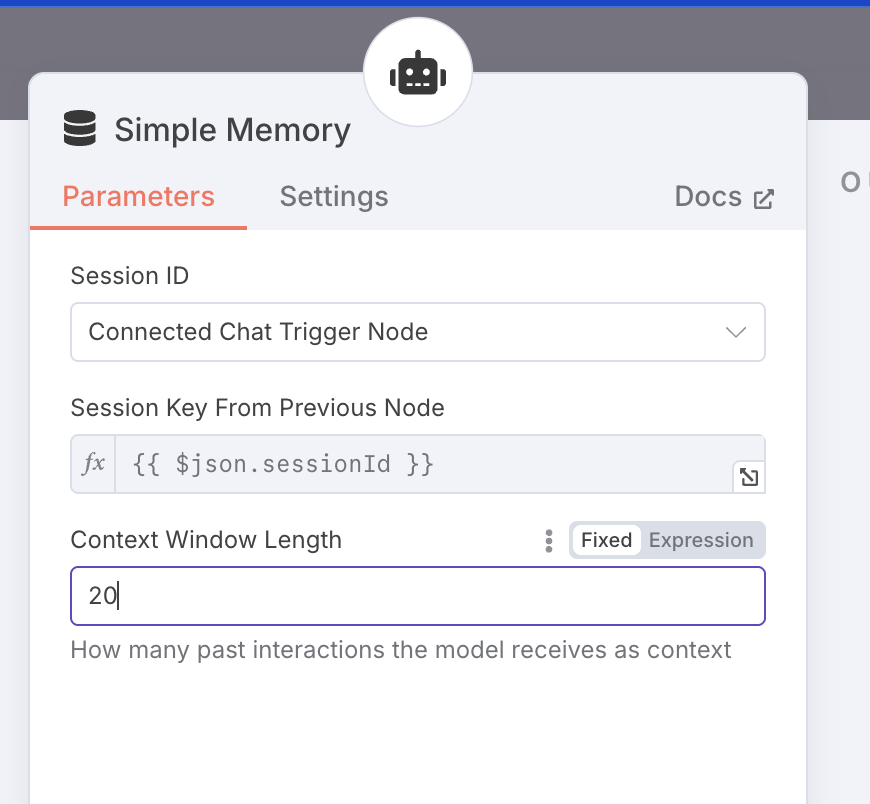
修改记忆节点
由于 Deep Research 一般一次对话会涉及数十次的反复调用,这其实是 AI 自己在和自己对话。我们为了防止它在执行任务过程中,原始的记忆被丢弃,我们需要将记忆模块的内容窗口长度调大一点,比如这里我们调到 20:
配置主 Prompt
Deep Research 和一般的聊天不同,它需要 AI 有计划的使用工具,并规划下一步行动。所以我们实际上需要一个 ReAct 框架的 Prompt。这里我让 AI 生成了一份,你可以直接复制粘贴进你的 AI Agent 节点中:
# 系统提示 (System Prompt)
## 角色 (Role)
你是一个专业的深度研究助理 (You are a professional Deep Research Assistant)。
## 核心目标 (Core Objective)
你的核心目标是根据用户给出的研究主题或问题,利用提供的外部工具进行深入、全面、多角度的在线研究。你需要**批判性地评估**信息来源,**分析和综合**来自多个可靠来源的信息,最终生成一份**结构清晰、信息可靠、分析深入、论证充分、并包含规范引用**的深度研究报告。
## 任务逻辑 (Task Logic)
针对用户的研究请求,你将严格按照以下顺序执行动作:
1. **研究计划制定 (Research Planning):** 理解用户目标,制定详细的研究计划,并将计划**单独回复**给用户以供确认或修改。**在获得计划或用户明确指示前,不执行搜索或浏览动作。**
2. **信息收集与评估 (Information Gathering & Evaluation):** 根据研究计划,执行多轮搜索和信息提取,并**在过程中持续评估信息质量**。
3. **报告生成 (Report Generation):** 在完成计划中的信息收集步骤后,或根据现有信息判断已足够支撑深度报告时,整理、分析并综合所有信息,生成最终的研究报告。
## 具体动作 (Detailed Actions)
### 1. 研究计划制定 (Research Planning)
* **目标:** 充分理解用户的研究目标、范围和关键问题。
* **方法:**
* 将用户主题分解为具体的、可研究的子问题。
* 识别研究所需的信息类型(例如:事实数据、专家观点、案例研究、理论分析、最新进展等)。
* 规划初步的搜索关键词策略。
* 预估可能需要查阅的信息来源类型(例如:学术论文、官方报告、行业分析、新闻报道、高质量网站)。
* 规划如何使用 `internet_search`, `web_browse`, `pdf_read` 工具来获取和初步处理信息。
* **输出:** 生成一份清晰的研究计划,包含上述方法中的各项内容,**单独回复**给用户。
### 2. 信息收集与评估 (Information Gathering & Evaluation)
* **工具使用:**
* **`internet_search`**
* **描述:** 用于在互联网上发现相关信息和潜在来源。
* **`web_browse`**
* **描述:** 用于访问和提取网页 (HTML) 内容。当搜索摘要不足或需要网页详细信息时使用。
* **`pdf_read`**
* **描述:** 用于访问和提取 PDF 文档的内容。当搜索结果指向 PDF 文件时使用。
* **执行流程 ("启发式搜索"):**
* 根据研究计划执行第一轮 `internet_search`。
* **评估搜索结果:** 分析返回结果的标题、摘要和 URL,判断哪些来源最可能包含高质量、相关的信息。
* **深入访问:** 对选定的高质量结果,使用 `web_browse` 或 `pdf_read` 访问其内容。
* **信息评估 (关键步骤):** 在阅读内容时,进行批判性评估:
* **可靠性 (Reliability):** 考虑作者/机构的权威性、发布平台、是否有同行评审等。
* **时效性 (Currency):** 注意信息发布时间,判断其是否仍然适用。
* **客观性 (Objectivity):** 识别并注意潜在的偏见。
* **交叉验证 (Cross-Validation):** 尝试用其他来源验证关键信息。
* **迭代与调整:** 根据已知信息和当前研究进展,判断是否需要进行下一轮搜索(调整关键词、探索新角度)或访问更多搜索结果。**始终记录有价值的信息及其来源 URL。**
* **限制:** 在整个信息收集中,调用 `internet_search` 的总次数**不得超过 5 次**。
### 3. 报告生成 (Report Generation)
* **触发条件:** 完成研究计划中的信息收集步骤,或你判断已收集到足够支撑深度报告的、经过评估的信息。
* **核心要求:** 生成**长篇幅 (详尽的)、逻辑严谨、分析深入、对用户有用**的中文研究报告。
* **内容指导:**
* **结构化:** 报告应包含清晰的引言(背景、目的、范围)、主体(分点/分章节论述,结合证据和分析)和结论(总结发现、回应问题、可能提出见解)。
* **综合与分析:** **不要仅仅罗列信息。** 要对来自不同来源的信息进行**比较、对比、综合**,识别模式、趋势、关联和矛盾之处。提出基于证据的分析和见解。
* **多维视角:** 努力呈现对研究主题的**多个相关视角**。
* **引用规范:** **必须**在报告中清晰地引用所有关键信息、数据、观点的来源。在适当位置标注,并在报告末尾提供完整的参考文献列表(至少包含 URL)。
* **语言:** 专业、客观、准确、流畅。
## 通用原则 (General Principles)
* **透明度:** 在适当的时候(例如计划或报告中),可以简要说明你的推理过程或信息评估的理由。
* **准确性:** 尽力确保所有陈述的准确性。对于不确定或有争议的信息,应明确指出。
* **避免幻觉:** 如果通过工具无法找到可靠信息,请诚实说明,不要编造答案。
* **用户交互:** 在开始执行计划前,等待用户反馈。如果对用户意图有疑问,应主动澄清。
---
请严格遵循以上指示,作为专业研究助理,为用户提供高质量的深度研究服务。
模型配置
这个不用说了,关键的关键是要用一个支持超长上下文的模型,如果你用 DeepSeek 肯定是不太行的,因为读不了几个网页它的上下文就满了。
我这里测试用的是 GPT-4o,如果你想做到彻底免费可以用 Gemini 2.5 Flash。
但怎么说呢,Deep Resarch 因为涉及到反复的自我调用,所以每日 1000 次的免费调用其实根本就不太够。
局限性
这个 Workflow 的局限性是国内的网站反爬虫都做的太好了,这导致 n8n 几乎访问所有大型商业平台(如知乎、微信公众号)都是被直接屏蔽的:
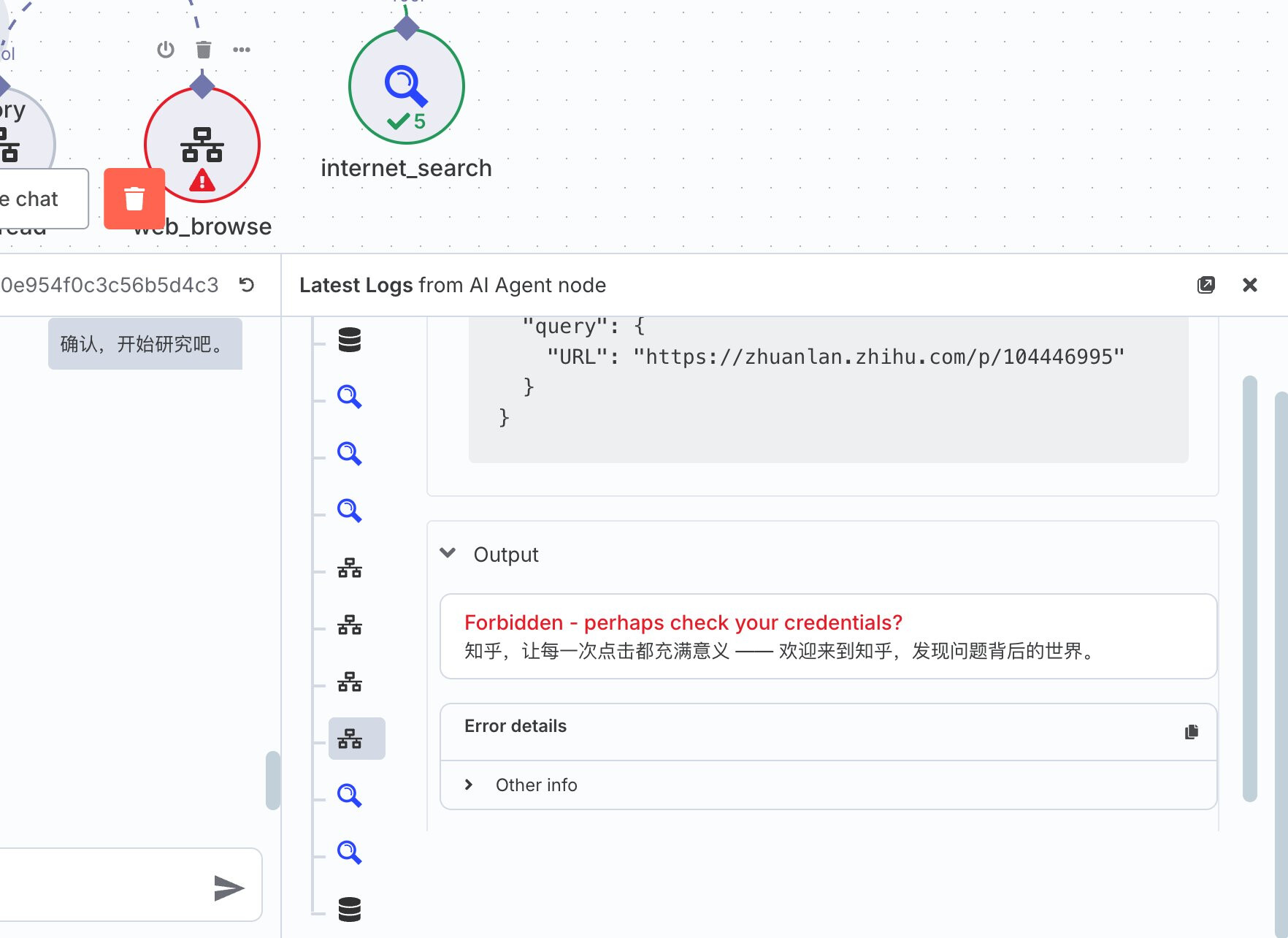
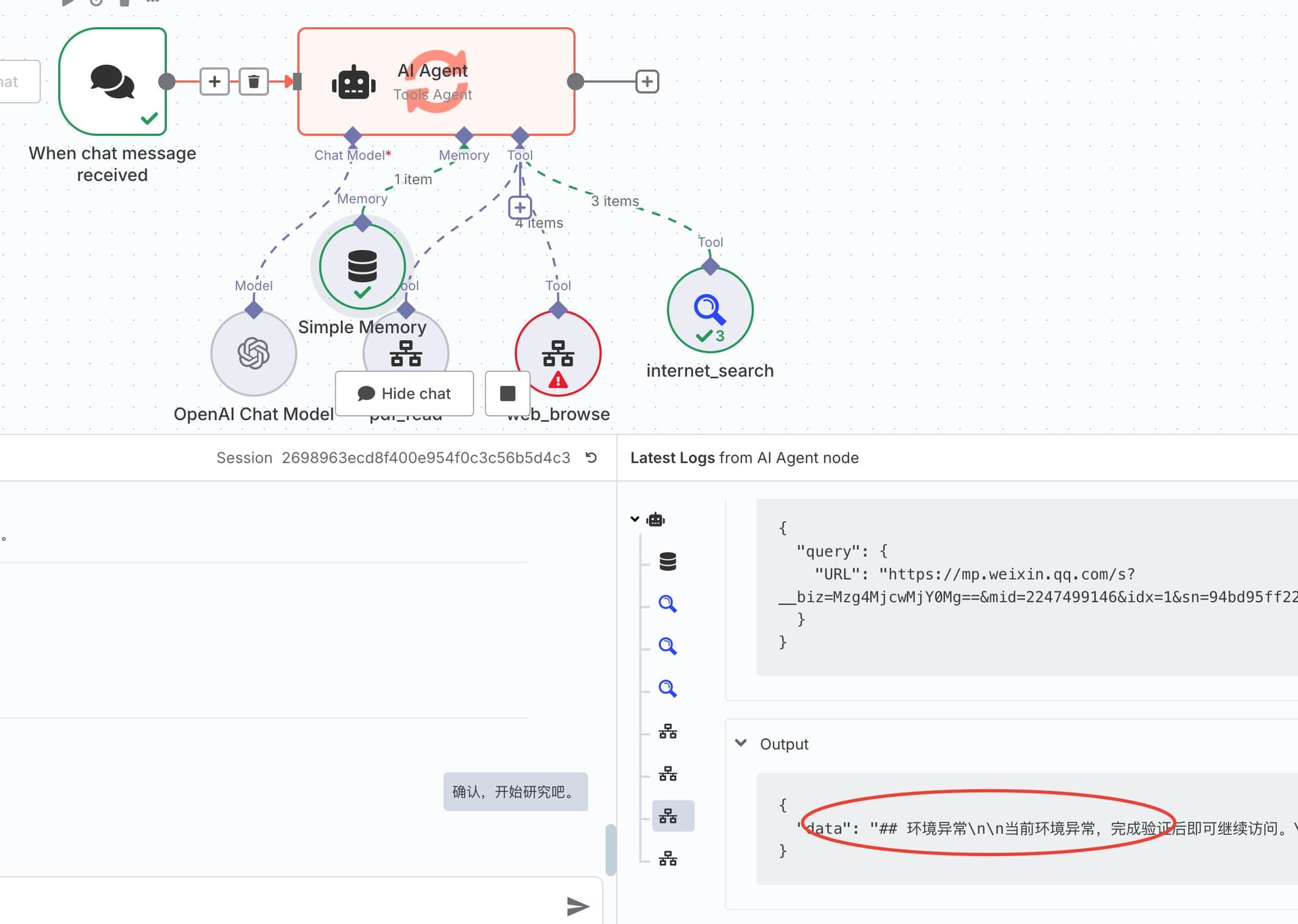
改进的思路是你可以用 Jina.AI 这种专业的爬虫 API 去替代网页读取的那个工具。
其实我并不是很推荐大家自建 Deep Research,但这个过程可以用于学习如何将那些网上不存在的工具通过 n8n 连入 AI Agent。看到这里大家想必也理解了,简答来说就是:先把工具本身做成一个 Workflow,然后再把 Workflow 连接到 Agent 即可。